- Welcome to our page.
- With us, you can book an individual Software Developer, or set-up a remote Scrum-Team, at Heidelsoft India.
- We are a premium-branded company, with high-end Indian resources.
- We deliver all technologies, to meet your software development needs.
Infopark, Kochi, India

Big Data Testing – All you need to know in a nutshell
AjeshBig Data is the term that is referred to as Data of Massive in size. This data could be either structured or Unstructured. Today’s most of the organizations owns a wide range of Data and this data plays a crucial role in their success. How Data can be a factor for the “Success” of an Organization? There comes the significance of Big Data and Analytics. Which helps, enterprises to understand patterns, reveal unknowns, describes personas, perspectives of End-users, Products or even the operation of a real-time system.
Big Data has several characteristics. Hence, they defined using 5 V’s.

Data Measurement List to understand how to represent the Size of Data in Big Data World

Why an Organization Requires Big Data testing?
The success of any enterprise depends on how fast they can capture newer markets and Customer base. How can they achieve this? Only the one enterprise that collects information about existing markets, Customers and operations to frame a prototype of new business strategies. These tacts are acquired from various and complex analytics report produced by Big Data. So, ensuring the quality and dependability of Data, that become the core part of a business ‘success’ comes first and foremost challenge for any enterprise. Thus, wins the relevance of Big Data testing in Enterprises.
Big Data process Architecture
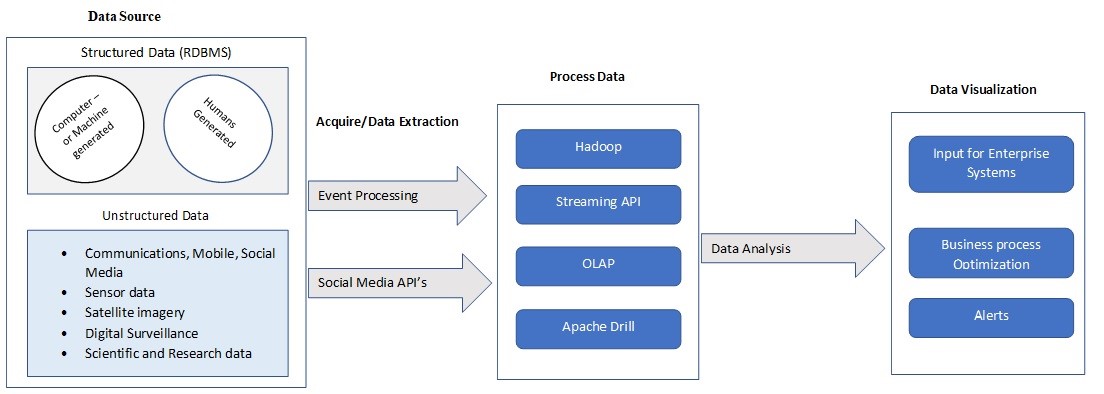
1) Feed data from many sources and analyze the new source of data from sources like social media platforms and Devices sensors.
2) Process massive volume of Data and make it available to the business for on-demand analytics.
3) Data Visualization in terms of Dashboards or Metric for further evaluations.
Big Data Testing Scenarios
Accounting the size and components, let us consider scenarios can be performed for Big Data Testing.
Data Ingestion/Staging Stage:
This is considered as the first stage of Big Data process. Here we validate structured or unstructured data taken from various sources mentioned. Data is feed to processing stage using tools Apache NiFi (a.k.a. Hortonworks DataFlow), StreamSets Data Collector (SDC), Gobblin, Sqoop, Flume, Kafka and the list goes on.
Data Processing:
To transform the data from different sources during this stage the one should touch every record incoming. Doing by that ensures the cleanness and standardization of Data for further process. There are couple of tools used at this stage to process. They are frameworks like Hadoop, Spark, Samza, Flink, etc.
Data Storage/Output validation:
This is the validation step, in which Business validates that the output from the big data application is correctly stored in the data warehouse. They also verify that the data is accurately being represented in the business intelligence system or any other target UI.
Performance Testing of Big Data Applications
As Big Data application dealt with a large quantity of Data, it is a must to perform Performance testing to understand Hardware resources utilizations such as Memory, CPU, IO read-write and Data loading and throughput.